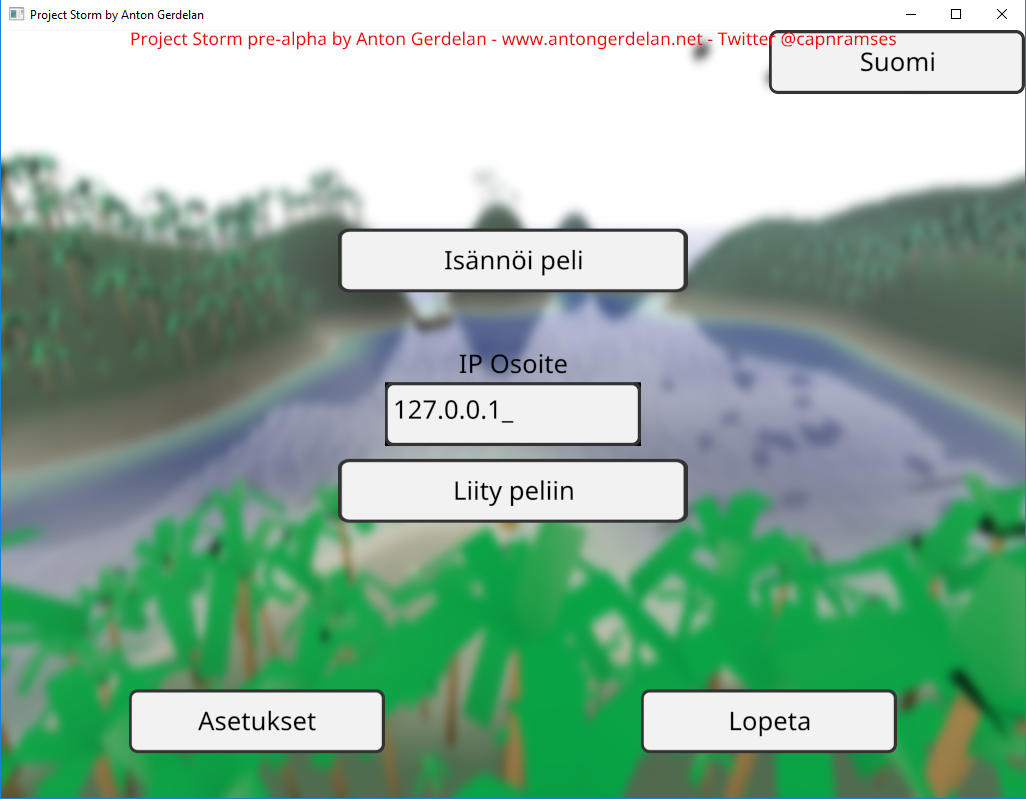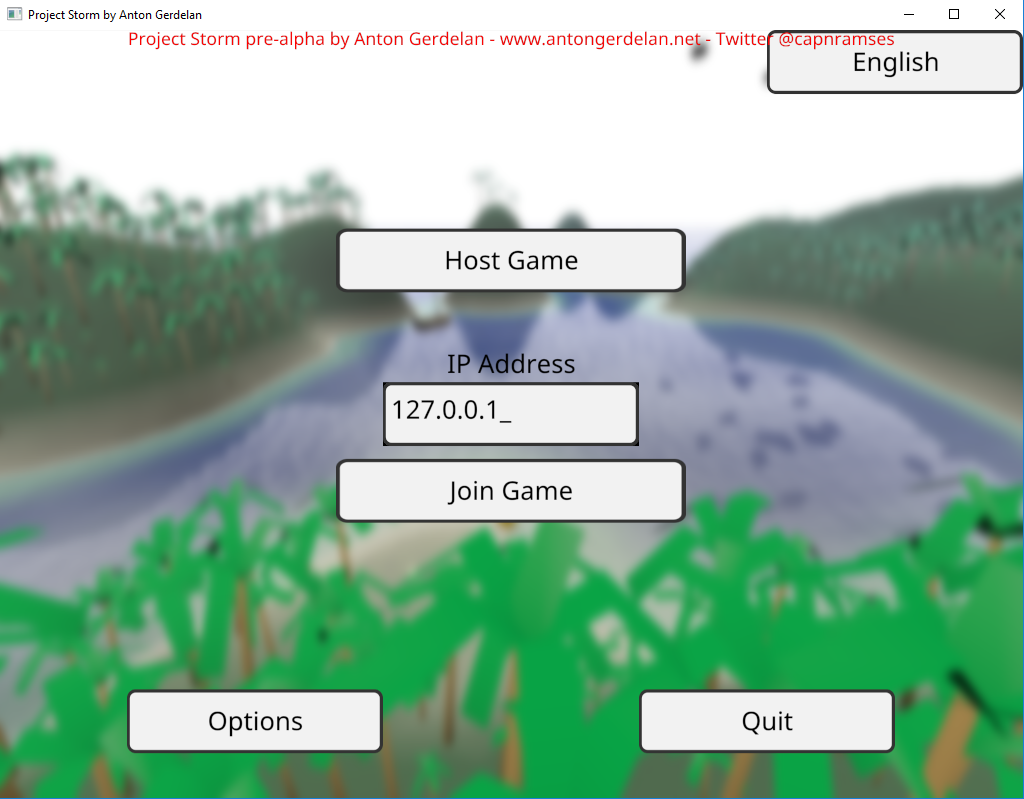
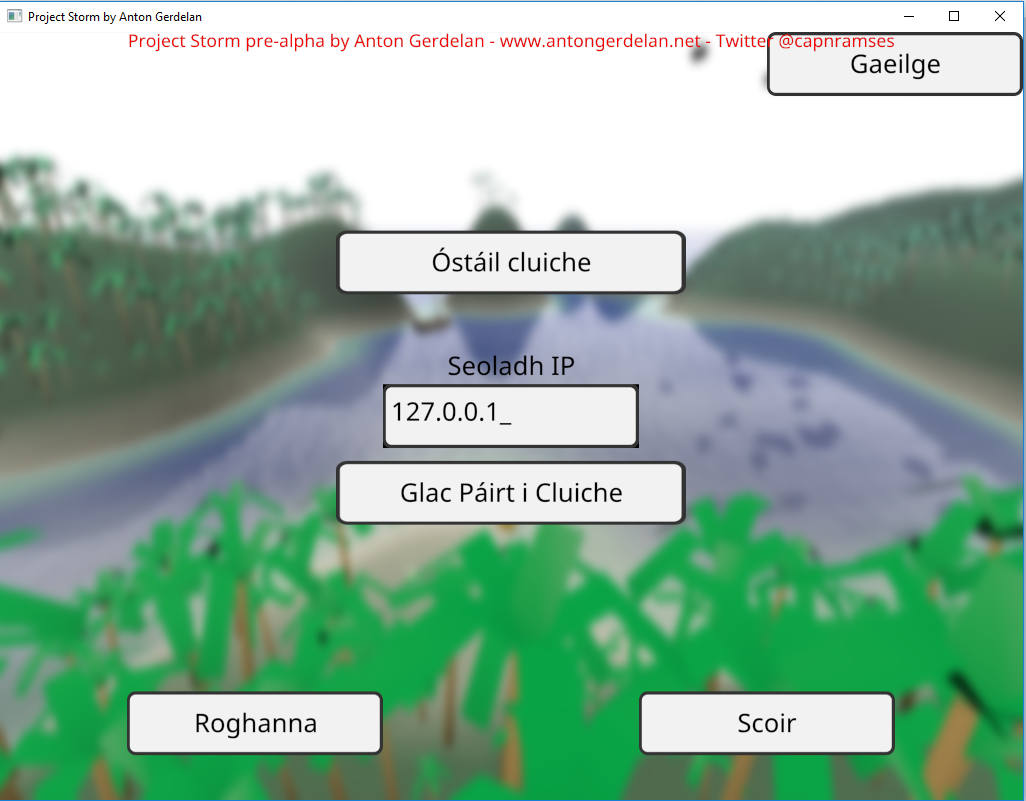
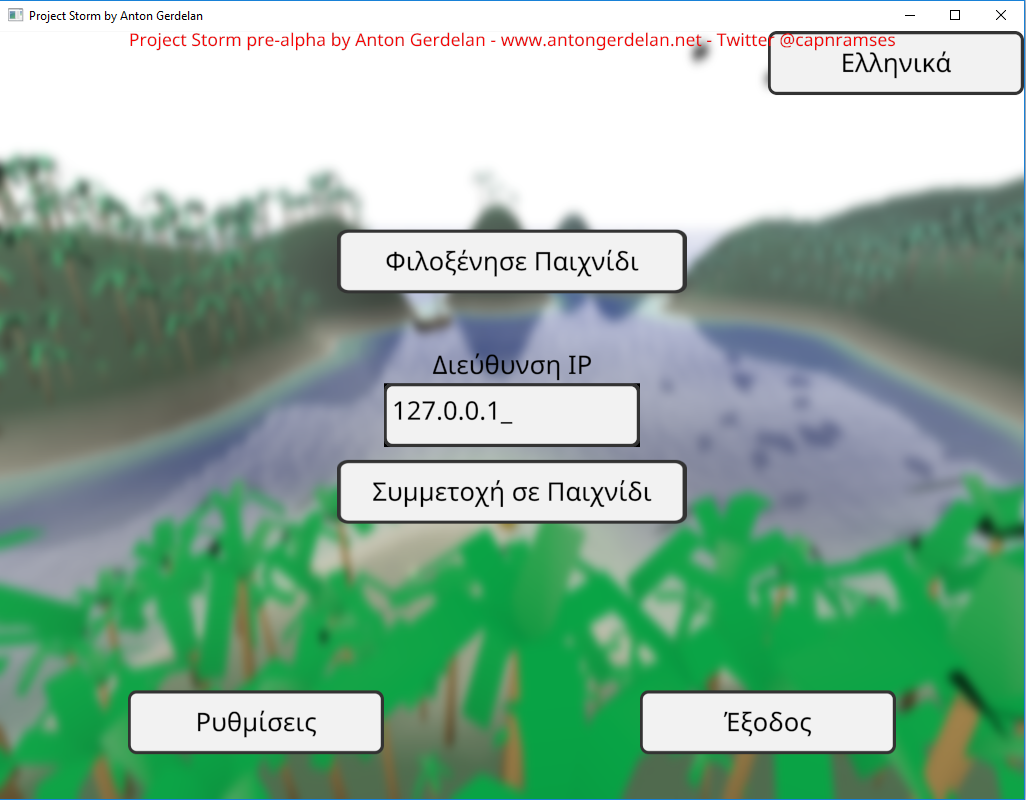
C and C++ ASCII strings can do most English text (above), but can't even handle accented characters as required by French, or Irish (below). This is extremely lame.
I have always been interested in languages. I have been adding multilingual text rendering support to my kick-around hobby game project over the last year or so. The project is written in C99 and OpenGL. Here's an overview of rendering text and how I support various other languages.
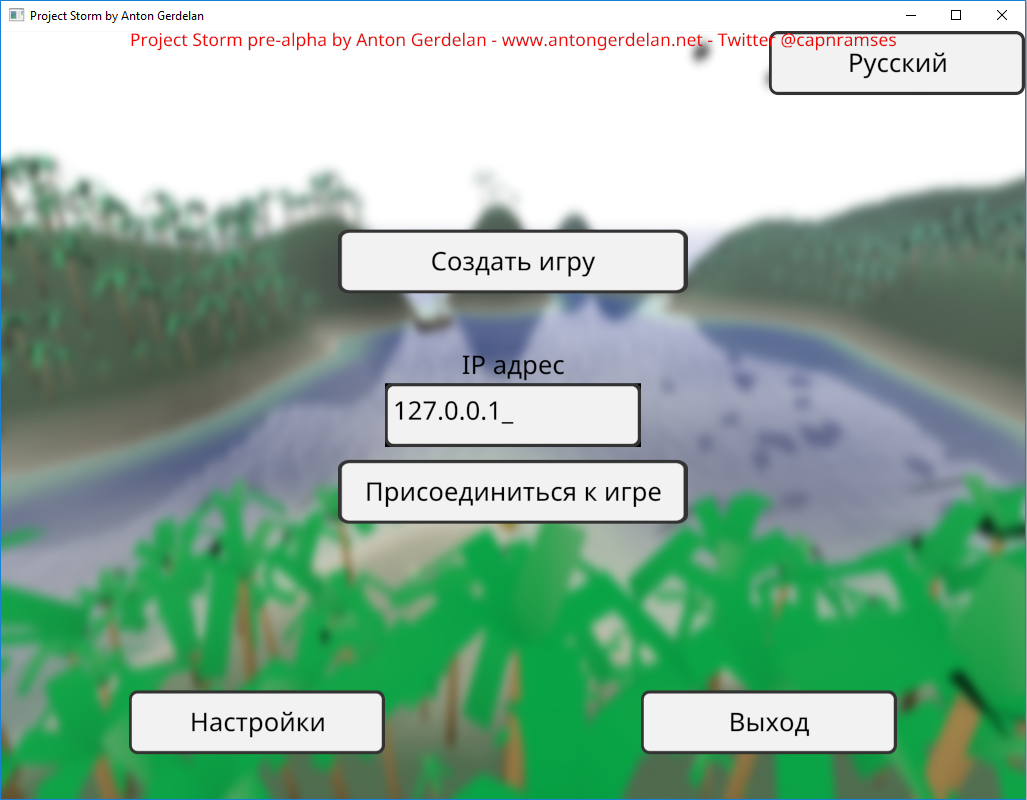
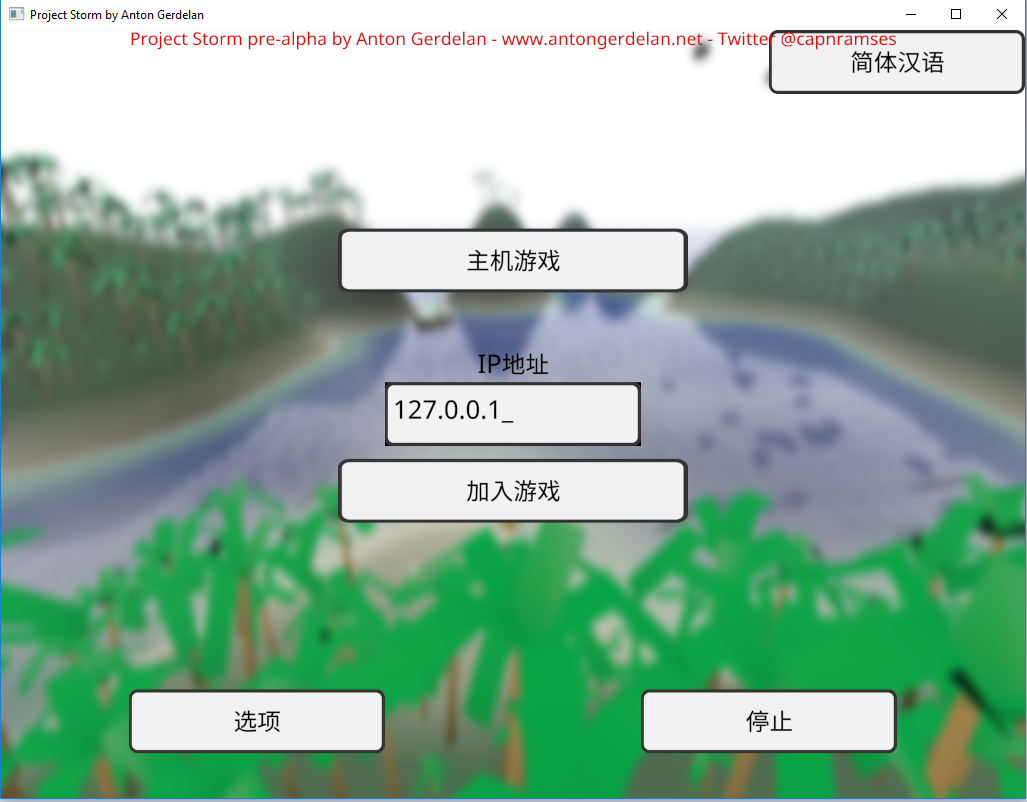
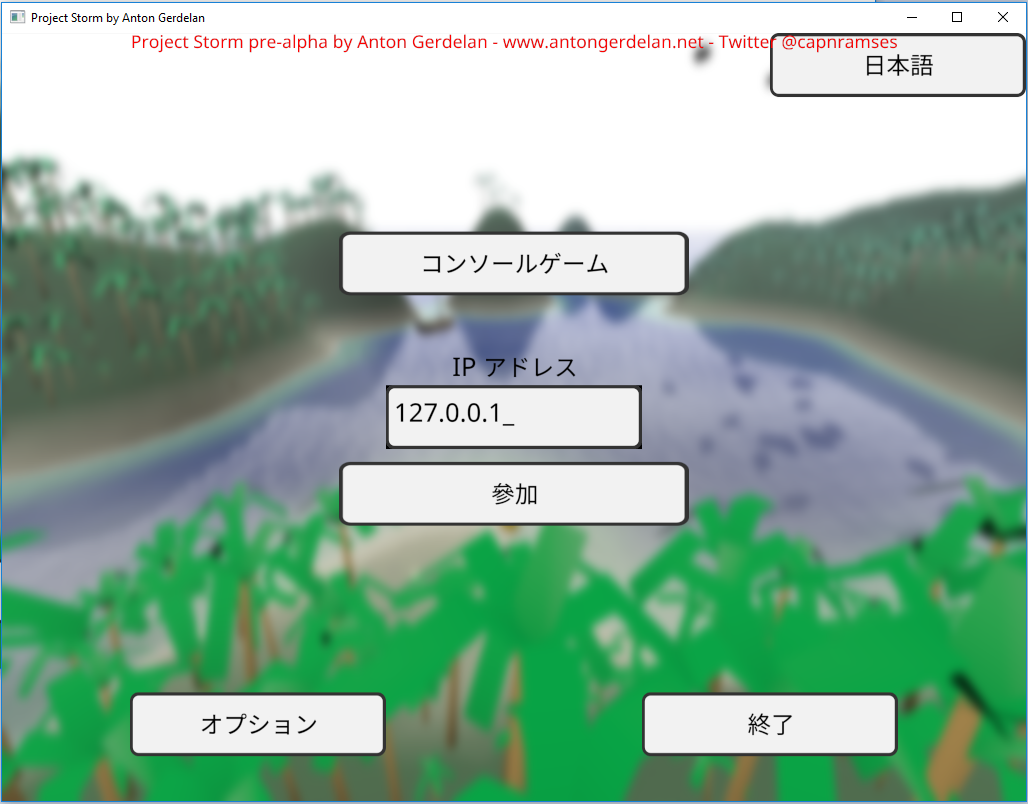
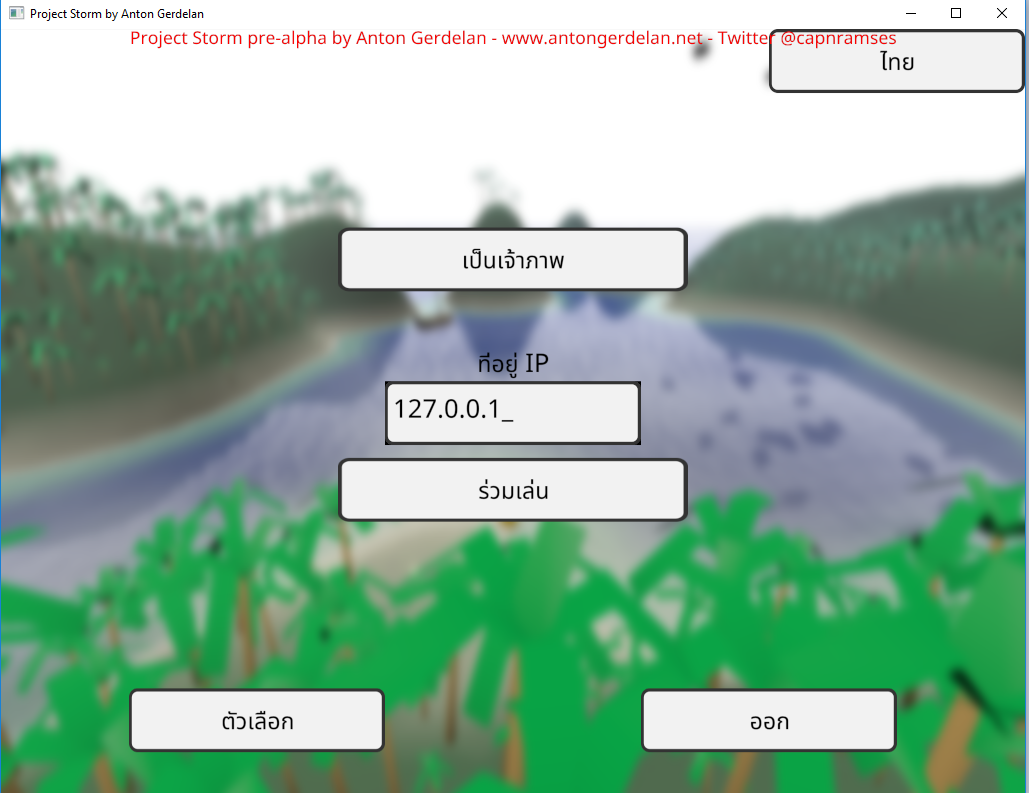
In code I refer to all human-readable strings by an enumerated code, rather than hard-code them. These correspond to a set of strings loaded from a file. This lets me easily switch languages and fix errors on the fly. I store all my strings in a UTF-8 encoded text file, which can store any language's string. A small army of helpful friends and people from the Internet provided a list of UI button translations to use.
It usually comes as a surprise to people learning computer graphics that graphics APIs do not provide text rendering - you have to build that in yourself. If you have a string of text you can use a font rasterisation library to render each character into a bitmap. You can then push these to the screen as textured quads, or into a bigger bitmap. That would be the most basic method - still quite a lot of work. There are not a lot of libraries around that do the whole job either - you can get pretty good font file reading and rasterisation from Freetype, but you have to size the quads to fit yourself, and write the texturing shaders. The library takes a bit of work to use correctly also. I wrote a guide to doing this in Anton's OpenGL 4 Tutorials. These days I've replaced Freetype in my projects with stb_truetype, which is less sophisticated but much lighter weight as a project dependency, and more inclined towards use in 3D graphics. It reads font files but also bakes and fits atlases (big combined images) for sets of Unicode codepoints (fits them all into a single big image which you can index into). For very sophisticated multilingual and font support the Qt libraries are very good, but come with a very hefty price tag for commercial projects. A new commercial entry is the Slug library, which looks like it does everything you might want.

If you want to render multi-lingual characters then you need to have a font that contains the character images (glyphs) for them. Most fonts are split into a few files - Chinese-Japanese-Korean (CJK), Thai, and Arabic are often separate files. The font you want to use may not have full multi-lingual support. You may also need to maintain a consistent look between alphabets. This is trickier than it sounds. Most fonts rendering Arabic characters or Chinese ideograms look a bit thin or light compared to the Latin characters. This may require some additional weighting to look consistent or some mix-and-matching of font files. Google Fonts usually have pretty good multi-lingual support and broad licences.
Basic text encoding of strings in the C and C++ languages only supports the ASCII character set. This is a very small subset of the Latin alphabets, and really only supports American English. In my opinion this is a very embarrassing oversight in the development of these programming languages. There are various double-wide or "wide" string encoding methods for C and C++ but they are inconsistently supported on different platforms, which is very annoying. They are tempting but do not use them! The best bet for adding language support to C or C++ is to use a Unicode encoding. Unicode calls characters codepoints, and each has a value in hex. The first 128 correspond to ASCII. An unsigned 32-bit integer can store any codepoint. You could use a whole new set of string functions that operate on 32-bit integers instead of 1-byte chars, but it is usually more convenient to use a unicode encoding method. I use UTF-8, which has the nice property that codepoints in the ASCII range are exactly the same char arrays as they were before. In UTF-8 other codepoints require 1-4 bytes to encode - so it's a form of compression. Other encoding methods are more consistent sizes but not compressed. JavaScript uses UTF-16 I believe. Go uses UTF-8. You do need a codepoint-to-utf8-char-array encoder and decoder pair of functions though. Mine are https://github.com/capnramses/apg/tree/master/apg_unicode. Your best bet is to keep all your strings in memory as UTF-8, and en/decode to whatever you need to interface with at the last moment.
The tricky thing, once you have moved to UTF-8, is that string functions can not assume one byte is equal to one codepoint. For example, you can still use strlen(), but now it returns the size in bytes of a string, but not necessarily the number of codepoints. More sophisticated C++ string processing will not work as expected - switch to just the C char array functions instead. The performance cost of looping over UTF-8 strings is now a little higher than it was with plain ASCII. Avoid doing this every frame during rendering.
There are tens of thousands of ideogram codepoints from the CJK set that are shared by East Asian languages - far too many to fit into an atlas. In this case it is a good idea to list all the strings of text required in Chinese, Japanese, and Korean, and only bake bitmaps for the glyphs that are actually required in the program. This means that you cannot support user-entered text. If you need this - you probably don't, nobody uses text-entered in-game chat these days, they all use Discord - I would rasterise bitmaps on demand. You could pre-cache the most-commonly used 10k or so, but it's probably not that useful to do.
Some fonts store a kerning table for each pair of codepoints. This depends on the font. Stylistically, some glyphs can be pushed closer together horizontally. A lower-case 'o' may be pushed under a 'V' to avoid looking too spaced out. Compare 'Vo' or 'VAV' in different fonts. You can fetch this additional spacing from the font. Stb_truetype can do this for you. Kerning support varies wildly between font rasterisation libraries and between fonts. This can make languages such as Thai notoriously difficult to render. stb_truetype did a good job of positioning Thai's glyph accents/modifier glyphs for me, where Freetype did not. Some fonts look good without kerning and do not provide kerning tables at all, and others look overly spaced out if you don't use their kerning tables.
In some languages and fonts, two particular codepoints next to each other can be substituted for a single ligature codepoint when rendering a string. Something like ae to æ for dæmon. I haven't added ligature support yet, but you can find official ligatures in Unicode documentation. This is probably most appropriate in Arabic text, but is not required for basic Arabic cursive (calligraphic) support.
Arabic-derived scripts, some Indian languages, Hebrew, and Aramaic are right-to-left languages. Most technical interfaces for East Asian languages seem to prefer left-to-right rows (the same as Western languages), but they can also be expressed in columns right-to-left or as right-to-left rows. Strings are always stored in memory in the order that they are written. This means that element 0 in an array is the left-most displayed character in an English string, but the right-most displayed character in Arabic. You can either change your string display function to be language-aware when laying out character bitmaps, or reverse a string's memory before displaying it. A string can also contain characters from several languages. You could split these into sub-strings first before processing to simplify string-parsing logic.
The memory order and screen display order of right-to-left languages often creates other complications. Word processing software may display the strings right-to-left but highlighting or hovering over string segments can flip around to reverse direction if the software has been made in Silicon Valley, which is very frustrating for the user's experience! The editor I'm writing this in has this problem.
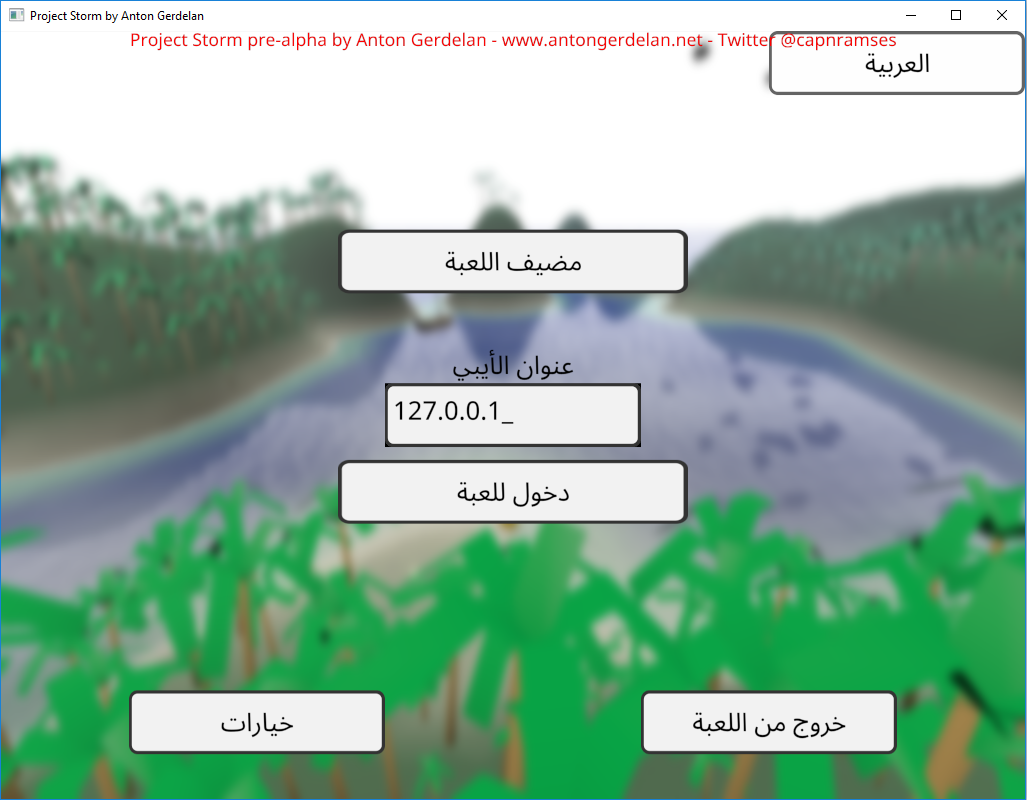
Arabic-derived scripts are always written in cursive. It is much easier, but incorrect, to display the glyphs separated. Each glyph in Arabic can have an isolated (stand-alone), initial (start of a cursive segment), medial (in between two cursive glyphs), or final (the last, left-most, glyph in a cursive segment) form. Getting this right requires some language and string-aware functions. Not every codepoint has one of every form. Arabic characters are stored in string memory by their base, individual codepoints, so you can use look-up tables to keep track of their cursive form options, and fetch the correct cursive codepoint alternative just before rendering. Not all codepoints have all of the forms, so you need to convert a string sequence to cursive form by checking the neighbouring codepoints and what forms they take, as well as the codepoint in question. But, the cursive joins all connect at the same, consistent points, so you can interchange the glyphs and don't need to manually draw the cursive connections.