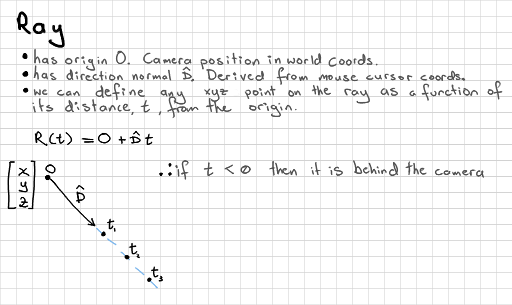
A ray expressed as origin O, direction D, and points as distances t along the ray.
This article gives a practical introduction to OpenGL compute shaders, and we start building a toy ray-traced renderer. You should be familiar with basic OpenGL initialisation, and know how to render a texture to a full-screen quad before starting this tutorial.
I delayed writing an OpenGL compute shader tutorial because I like to have first stepped on enough pitfalls that I can help people with common mistakes, and have enough practical experience that I can suggest some good uses. It occurs to me that I haven't ever written about writing a ray-tracing or path tracing demo. Playing with ray-traced rendering is certainly a lot of fun, is not particularly difficult, and is a nice area of graphics theory to think about. Every graphics programmer should have a pet ray-tracer. Certainly, you can write a ray tracer completely in C code, or into a fragment shader, but this seems like a good opportunity to try two topics at once. Let's do both!
Compute shaders are a general purpose shader - meaning using the GPU for tasks other than drawing triangles - GPGPU programming. There are stand-alone tools and libraries that use the GPU for general purpose tasks. Nvidia's CUDA, and OpenCL are very popular for jobs that want the GPU's parallel floating-point calculation power. We see this used for running physics simulations and experiments, image processing, and other tasks that work well in small, parallel jobs or batches. It would be nice to have access to both general 3d rendering shaders, and GPGPU shaders at once - in fact they may share information. This is the role of the compute shader in OpenGL. Microsoft's Direct3D 11 introduced compute shaders in 2009. Compute shaders were made part of core OpenGL in version 4.3, mid-year 2012.
Because compute shaders do not fit into our staged shader pipeline we have to set up a different type of input and output. We can still use uniform variables, and many of the tasks are familiar.
Ray tracing works differently to our raster graphics pipeline. Instead of transforming and colouring geometry made entirely of triangles, we have an approach closer to the physics of real light rays (optics). Rays of light are modeled as mathematical rays. Reflections on different surfaces are tested mathematically. This means that we can describe each object in our scene with a mathematical equation, rather than tessellating everything into triangles, which means we can have much more convincing curves and spheres.
Ray tracing is typically more computationally expensive than rasterised rendering, which is why we have not used it for real-time graphics in the past. It is the rendering approach of choice for animated movies because it can produce very high-quality results. Full quality ray-traced animations often take days to render and studios make use of cluster computer farms.
We are going to start with something really simple, and you'll see it's easy enough to progressively add features later if you like.
The compute shader has some new built-in variables, which we can use to determine what part of the work group an our shader is processing. If we are writing to an image, and have defined a 2d work group, then we have an easy way to determine which pixel to write to.
| uvec3 gl_NumWorkGroups | global work group size we gave to glDispatchCompute() |
| uvec3 gl_WorkGroupSize | local work group size we defined with layout |
| uvec3 gl_WorkGroupID | position of current invocation in global work group |
| uvec3 gl_LocalInvocationID | position of current invocation in local work group |
| uvec3 gl_GlobalInvocationID | unique index of current invocation in global work group |
| uint gl_LocalInvocationIndex | 1d index representation of gl_LocalInvocationID |
These variables are useful in determining which pixel in an image to write to, or which 1d array index to write to.
It is also possible to set up shared memory between compute shaders with the shared keyword. We won't be doing that in this tutorial.
First create a simple OpenGL programme, with a 4.3 or newer context, that renders a texture to a full-screen quad. I won't detail that here.
We can set up a standard OpenGL texture that we write to from our compute shader. Remember the internal format parameter that you give to glTexImage2D() because we must specify that same format in the shader code. We also need to remember the dimensions of the texture.
// dimensions of the image int tex_w = 512, tex_h = 512; GLuint tex_output; glGenTextures(1, &tex_output); glActiveTexture(GL_TEXTURE0); glBindTexture(GL_TEXTURE_2D, tex_output); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA32F, tex_w, tex_h, 0, GL_RGBA, GL_FLOAT, NULL); glBindImageTexture(0, tex_output, 0, GL_FALSE, 0, GL_WRITE_ONLY, GL_RGBA32F);
In order to write to a texture we use image storing functions in the shader. OpenGL treats "image units" slightly differently to textures, so we call a glBindImageTexture() function to make this link. Note that we can set this to "write only".
It is up to us how we define and divide up our pile of work to do between compute shader invocations. First we should check what the maximum size of the total work group that we give to glDispatchCompute() is. We can get the x, y, and z extents of this:
int work_grp_cnt[3];
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 0, &work_grp_cnt[0]);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 1, &work_grp_cnt[1]);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 2, &work_grp_cnt[2]);
printf("max global (total) work group counts x:%i y:%i z:%i\n",
work_grp_cnt[0], work_grp_cnt[1], work_grp_cnt[2]);
We can also check the maximum size of a local work group (sub-division of the total number of jobs). This is defined in the compute shader itself, with the layout qualifier. These two limits might help us decide how to divide our work:
int work_grp_size[3];
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 0, &work_grp_size[0]);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 1, &work_grp_size[1]);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 2, &work_grp_size[2]);
printf("max local (in one shader) work group sizes x:%i y:%i z:%i\n",
work_grp_size[0], work_grp_size[1], work_grp_size[2]);
We can also determine the maximum number of work group units that a local work group in the compute shader is allowed. This means that if we process a 32x32 tile of jobs in one local work group, then the product (1024) must also not exceed this value:
glGetIntegerv(GL_MAX_COMPUTE_WORK_GROUP_INVOCATIONS, &work_grp_inv);
printf("max local work group invocations %i\n", work_grp_inv);
The best balance of local work group size depends on your device. It might be a good idea then to let the user tweak the size of the local work groups to get better performance, within some safe limits.
We can start with the following, simple, set-up. You may tweak this later:
The compute shader looks a lot like any other GLSL shader, with some important differences. Firstly, remember to define GLSL version 4.3 or newer at the top of your shader!
#version 430 layout(local_size_x = 1, local_size_y = 1) in; layout(rgba32f, binding = 0) uniform image2D img_output;
The first layout qualifier defines the size of the local work group - note that this is handled behind the scenes - we don't need to adjust our shader if we make the local work group larger. We decided to start with a size of 1 pixel - 1x1. It is also possible to put 1d or 3d dimensions here if your work group has a different structure.
The second layout qualifier defines the internal format of the image that we set up. Note that we use an image2D uniform, rather than a texture sampler. This gives us the ability to write to any pixel that we want.
void main() {
// base pixel colour for image
vec4 pixel = vec4(0.0, 0.0, 0.0, 1.0);
// get index in global work group i.e x,y position
ivec2 pixel_coords = ivec2(gl_GlobalInvocationID.xy);
//
// interesting stuff happens here later
//
// output to a specific pixel in the image
imageStore(img_output, pixel_coords, pixel);
}
We set a base colour for the image (black), which we can add to later. We access a built-in variable gl_GlobalInvocationID to find where in the work group space our invocation is - and we use this to tell which pixel we should be modifying. We write our final colour to this position in the output image.
GLuint ray_shader = glCreateShader(GL_COMPUTE_SHADER); glShaderSource(ray_shader, 1, &the_ray_shader_string, NULL); glCompileShader(ray_shader); // check for compilation errors as per normal here GLuint ray_program = glCreateProgram(); glAttachShader(ray_program, ray_shader); glLinkProgram(ray_program); // check for linking errors and validate program as per normal here
We can compile our shader program with just this one shader in it. We of course have another shader programme for rendering our final texture to a quad, and we can get it to read from our new texture.
My drawing loop looks as follows. Note that the compute shader dispatch looks as if it's another drawing pass. I set up the work group dimensions here to match my texture dimensions, and put a 1 for the z axis.
// drawing loop
while(!glfwWindowShouldClose(window)) {
{ // launch compute shaders!
glUseProgram(ray_program);
glDispatchCompute((GLuint)tex_w, (GLuint)tex_h, 1);
}
// make sure writing to image has finished before read
glMemoryBarrier(GL_SHADER_IMAGE_ACCESS_BARRIER_BIT);
{ // normal drawing pass
glClear(GL_COLOR_BUFFER_BIT);
glUseProgram(quad_program);
glBindVertexArray(quad_vao);
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, tex_output);
glDrawArrays(GL_TRIANGLE_STRIP, 0, 4);
}
glfwPollEvents();
if (GLFW_PRESS == glfwGetKey(window, GLFW_KEY_ESCAPE)) {
glfwSetWindowShouldClose(window, 1);
}
glfwSwapBuffers(window);
}
To make sure that the compute shaders have completely finished writing to the image before we start sampling, we put in a memory barrier with glMemoryBarrier() and the image access bit. You can instead use GL_ALL_BARRIER_BITS to be on the safe side for all types of writing. In larger code you would prefer to put the barrier call closest to the code that actually samples the texture, so that you don't introduce any unnecessary waits (thanks to @g_truc and @SaschaWillems2 for pointing this out!). I bind my new texture, which I display by drawing my full-screen quad. Now, if this compiles you can try changing the base colour to test that it works. If so you have mastered the basics of compute shaders!
We can hard-code our scene into the compute shader. First we work out the ray for the current pixel. A ray is defined as a 3d origin, and a 3d direction. We want to spread the origins over all of our pixels, and we can normalise this to an arbitrary view size of -5.0 to 5.0 on x and y. We know that the rays can all point forwards in an orthographic projection, so we can also arbitrarily say that this is the -z direction:
float max_x = 5.0; float max_y = 5.0; ivec2 dims = imageSize(img_output); // fetch image dimensions float x = (float(pixel_coords.x * 2 - dims.x) / dims.x); float y = (float(pixel_coords.y * 2 - dims.y) / dims.y); vec3 ray_o = vec3(x * max_x, y * max_y, 0.0); vec3 ray_d = vec3(0.0, 0.0, -1.0); // ortho
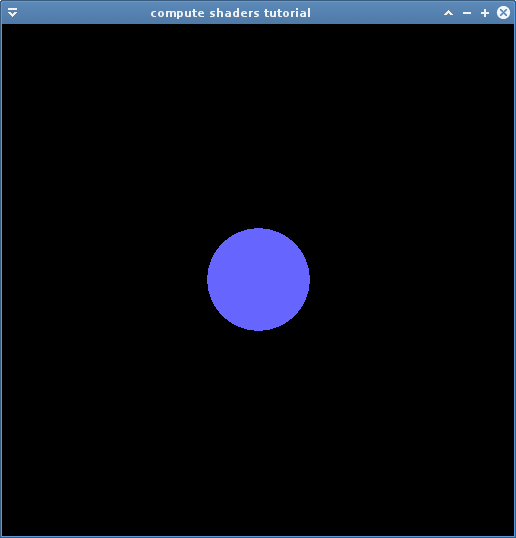
I want to have a sphere in my scene, which is defined as a 3d centre position, and radius:
vec3 sphere_c = vec3(0.0, 0.0, -10.0); float sphere_r = 1.0;
We can see that should be in the centre of view, taking up only some of the scene, and in front of the eye.

We can do a ray-sphere intersection test to determine if each pixel can "see" the sphere. In a more complex scene you should test for more possibilities - perhaps the sphere is behind the camera.
vec3 omc = ray_o - sphere_c;
float b = dot(ray_d, omc);
float c = dot(omc, omc) - sphere_r * sphere_r;
float bsqmc = b * b - c;
// hit one or both sides
if (bsqmc >= 0.0) {
pixel = vec4(0.4, 0.4, 1.0, 1.0);
}
Where bsqmc is "b squared, minus c" from my diagram, which is used in the test cases at the bottom of the diagram.

You might consider adding Phong or more realistic lighting models, reflections, refractions (perhaps both with a maximum number of bounces), lights, shadows, animations, perspective, or rendering to an image series for a video.
Maintaining an interactive ray tracer (with a user-controlled camera, for example) would be an optimisation challenge. Can you find a way to add a ray tracing effect into an existing real-time rasterised rendering?
Experimenting with rendering in tiles might be beneficial to your rendering time.